AWS Bedrock으로 내가 고른 책 내용 아는 챗봇 만들기
작년 Chat-GPT가 나온 이후로, 생성형 AI(Gen-AI)에 대한 관심이 뜨거운데요. 여기저기 AI챗봇 서비스가 나오고, Dall-E나 Stable Diffusion을 사용한 게임 개발 책이 나오는 등 정말 빠르게 다양한 도메인에서 활용되고 있는 것 같습니다. 회사에서 사용하고 있는 AWS에서 매해 개최하는 컨퍼런스인 Re:Invent 에서도 그것을 엿볼 수 있는데, Re:Invent 2022까지만 해도 컴퓨트나 네트워크 및 스토리지, 데이터 웨어하우스 기능 같은 CSP 기술(및 그것을 활용한 관리형 서비스)에 대한 이야기가 대부분이었습니다. 하지만 Re:Invent 2023에서는 이미 존재하던 많은 CSP 서비스(컴퓨트, 네트워크, 스토리지…)들에 Amazon Q를 얹어 사용성을 높였다는 이야기가 아주 많이 나왔습니다. 더해, Gen-AI를 손쉽게 사용할 수 있는 새로운 관리형 서비스인 AWS Bedrock도 공개가 되었습니다.
최근 AWS에서 Gen-AI Enablement Program을 열었고, 그 행사에 참여하는 기회를 얻었는데요, 행사에서는 AWS Bedrock을 어떻게 활용할 수 있는지 다양한 예시를 직접 Hands-on workshop으로 경험할 수 있었고, 그 중 RAG를 사용해 LLM에 문서나 회사 도메인 문서를 알려주는것을 다시 해보며 정리해봤습니다.
Bedrock은 한국에서 흔히 “기반암”이라고 번역됩니다. 모든 토양의 기반에 있는 돌 들을 기반암이라고 부릅니다. 영어로는 관용어처럼 어떤 것들의 기반이 되는 개념을 Bedrock이라고 부르기도 하는데요. 이 서비스가 어떤 역할을 하는지 몰랐을 때는 너무 추상적으로 다가왔지만, 살짝 개념을 알고 보니 Amazon Bedrock은 이름을 아주 직관적으로 지은 것 같습니다.
문서에서 직접 가저온 서비스 정의는 다음과 같습니다;
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
영어가 아주 길지만, 키워드들을 보면 foundation Model을 single API로 사용할 수 있게 해주는 fully managed service인 것을 알 수 있습니다. 쉽게 말해, Gen-AI 기능이나 제품을 쉽게 만들어 주는 관리형 서비스입니다.
여기서 말하는 Foundation model은 서비스를 사용하는데 기본이 되는 모델들을 말하고, 다양한 AI 회사들에서 개발한 텍스트/이미지/임베딩 모델을 제공하고 있습니다. 
- 이미지 모델: 이미지를 생성하거나/같은 개념을 다시 그리거나/일부를 다시 그리거나/이미지 유사성 분석 등
- 텍스트 모델: 텍스트를 분석하거나/chat-gpt같이 활용하는 등
- 임베드 모델: 텍스트를 임베딩 벡터로 분석하는 등
모델별로 다양한 사용 예시가 있습니다.
이 모델들을 가지고, Bedrock에서는;
- API를 통해 Foundation model이나 Custom model을 사용
- Foundation model을 활용해 Custom model을 생성(Fine-Tune/Pre-Train)
- Foundation model 및 그 모델에 들어가는 인자값을 바꿔가며 테스트(Playground)
- 모델이 접근 및 활용할 수 있도록 Knowledge Base생성
을 할 수 있습니다.
그럼 이제, 워크샵 내용 중 인상 깊었던 것을 정리해보겠습니다.
흔히 저희가 사용하는 LLM 서비스(흔히 말하는 Chat-GPT)는 한계가 있습니다. 특정 시점까지의 데이터만 가지고 학습이 이루어지는 특성 상, 최신 데이터를 가지고 있지 못합니다. 그렇기에, 최신 정보가 필요한 질문을 하게 되면 아주 일반적이거나 과거의 정보를 답변을 하게 됩니다. 더해서, 학습되지 않은 정보를 가지고 답변을 하려다 보면 어처구니 없는 답변(Hallucination)이 나오기도 합니다. (Pic)
이것을 극복하기 위해, 우리는 LLM 모델에 특정 정보를 알려 줄 수 있습니다. 그 방법 중 대표적인 것이 모델의 입력인 프롬프트로 직접 주는 것, 그리고 RAG를 사용하는 것 입니다.
프롬프트로 LLM 모델에 정보를 넣어주는 것은 간단하게 떠올릴 수 있는 해결책입니다. 모델의 입력으로 미리 알고 있어야 하는 사실들을 전달하고 나면, 그 이후 LLM은 문맥을 유지하며 해당 사실을 사용해 답변을 할 수 있습니다.

왼쪽 그림을 보면, 아무런 사전 지식이 없는 모델은 아주 일반적인 답변을 하는 것을 확인 할 수 있습니다. 그에 반해 프롬프트로 K8s의 오퍼레이터 패턴에 대해 알려 준 모델은 그 뒤 답변에서 우리가 원하는 K8s 오퍼레이터 패턴에 대해 잘 답변하는 것을 확인할 수 있습니다.
하지만 이렇게 프롬프트로 개념을 전달하는 것은 한계가 있습니다. 일단 모델에 전달할 수 있는 토큰 길이 제한이 있고, 모델을 사용할 때 마다 매 번 프롬프트를 전달해 문맥을 만들어 줘야 해 많은 양의 정보를 전달하는데는 어려움이 있습니다.
이 어려움은 RAG를 사용하면 극복이 가능합니다.
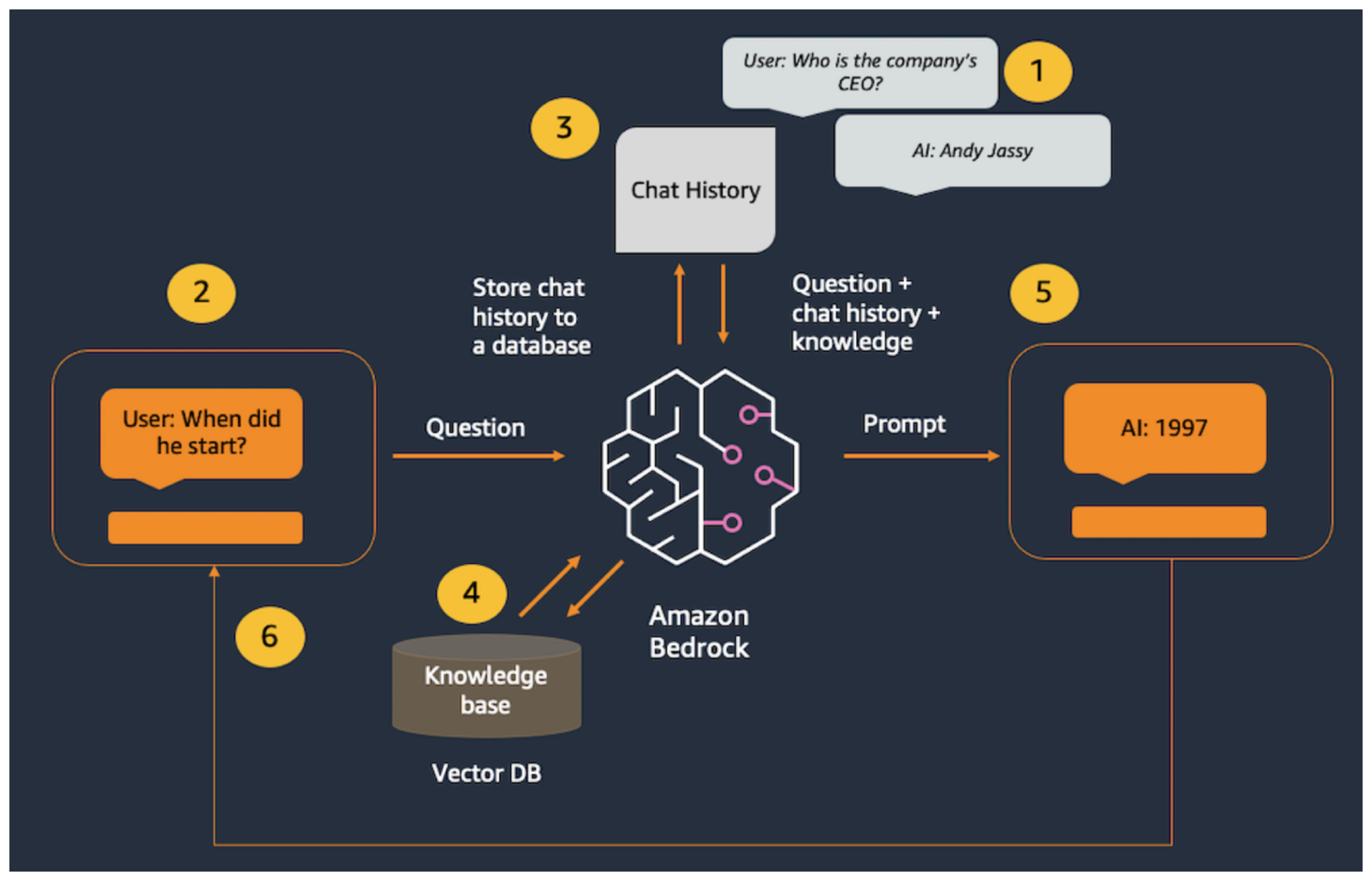
RAG(Retrieval-Augmented Generation)은, 어떤 벡터 데이터베이스에 LLM이 접근할 수 있는 정보들을 벡터화하여(임베딩) 저장하는 것으로 시작합니다. 정보들을 정제(우리의 경우 1000자 미만의 문장으로 쪼개)하고 정보를 모델이 이해할 수 있는 형태로 바꿔(임베딩) 벡터 데이터베이스에 저장하고 나면, LLM은 응답을 생성할 때 해당 벡터 데이터베이스에 있는 정보를 활용하여 답변을 하게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
def get_index(): #애플리케이션에서 사용할 인메모리 벡터 저장소를 생성하고 반환합니다.
embeddings = BedrockEmbeddings(
credentials_profile_name=os.environ.get("BWB_PROFILE_NAME"), #AWS 자격 증명에 사용할 프로필 이름을 설정합니다(기본값이 아닌 경우)
region_name=os.environ.get("BWB_REGION_NAME"), #리전 이름을 설정합니다(기본값이 아닌 경우)
endpoint_url=os.environ.get("BWB_ENDPOINT_URL"), #엔드포인트 URL 설정(필요한 경우)
) #Titan Embeddings 생성합니다.
pdf_path = "리눅스 커널 내부구조_OCR.pdf" #이 이름을 가진 로컬 PDF 파일을 가정합니다.
loader = PyPDFLoader(file_path=pdf_path) #PDF 파일 로드하기
text_splitter = RecursiveCharacterTextSplitter( #텍스트 분할기 만들기
separators=["\n\n", "\n", ".", " "], #(1) 단락, (2) 줄, (3) 문장 또는 (4) 단어 순서로 청크를 분할합니다.
chunk_size=1000, #위의 구분 기호를 사용하여 1000자 청크로 나눕니다.
chunk_overlap=100 #이전 청크와 겹칠 수 있는 문자 수입니다.
)
index_creator = VectorstoreIndexCreator( #벡터 스토어 팩토리 만들기
vectorstore_cls=FAISS, #데모 목적으로 인메모리 벡터 저장소를 사용합니다.
embedding=embeddings, #Titan 임베딩 사용
text_splitter=text_splitter, #재귀적 텍스트 분할기 사용하기
)
index_from_loader = index_creator.from_loaders([loader]) #로드된 PDF에서 벡터 스토어 인덱스를 생성합니다.
return index_from_loader #클라이언트 앱에서 캐시할 인덱스를 반환합니다.
1
2
3
4
5
6
7
8
9
def get_rag_chat_response(input_text, memory, index): #chat client 함수
llm = get_llm()
conversation_with_retrieval = ConversationalRetrievalChain.from_llm(llm, index.vectorstore.as_retriever(), memory=memory)
chat_response = conversation_with_retrieval({"question": input_text}) #사용자 메시지, 기록 및 지식을 모델에 전달합니다.
return chat_response['answer']
간략화한 코드를 보면, PDF파일을 열어 텍스트를 1000자 미만의 문장으로 나누는 text_splitter(RecursiveCharactorTextSplitter)를 선언한 뒤 index_creator(VectorStoreIndexCreator)를 만들고, 파일 로드를 통해 인덱스를 만드는 것을 확인 할 수 있습니다.
그 이후, 모델을 호출하는 것은 간단합니다. 질의할 텍스트와 인덱스를 지정해 conversation_with_retrivieal()을 호출하기만 하면 벡터 데이터베이스를 참고해 답변을 이끌어낼 수 있습니다.
결과를 확인해보면,


위 두 예시는 각각 “쿠버네티스 패턴”이라는 책, “리눅스 커널 내부구조” 라는 책의 내용을 넣어 답변을 받은 것입니다. RAG를 사용하지 않은 모델에서는 아주 일반적인 답변이 왔었는데, 각 책의 내용을 활용해 답변을 받을 경우 의도한대로 책의 내용을 잘 참조해 답변이 오는것을 확인할 수 있습니다.
추가로, 벡터 데이터베이스에 최신 데이터를 계속해서 입력해준다면 최신 내용을 답변하지 못하는 문제점도 해결할 수 있게 됩니다.
이 예시 외에도 다양한 hands-on을 진행했었는데요,
- 맵리듀스 패턴을 활용해 문서를 요약
- 텍스트에서 내용을 JSON/CSV형태로 추출
- 이미지 검색(이미지 간 유사도 확인)
- 이미지 임페인팅
등 여러 Foundation model의 사용례가 있었습니다.
다만 아쉬운 점은, 한국어로만 입력을 줬을 때 대체로 잘 답변해줬지만 중간중간 한국에서만 사용하는 단어나 개념에 대해서는 다루기 힘들어 했다는 점이 있었습니다. 이 것은 Foundation model들 중 아직 한국어에 특화된 모델이 없는데서 오는 한계라고 볼 수 있습니다.
Amazon Bedrock을 간단하게 써보니 AI 관련된 깊숙한 지식 없어도 상당히 쉽게 사용할 수 있도록 구성이 된 것 같습니다. 만약 Gen-AI 서비스나 기능을 개발한다면, 필요시 (MS-OpenAI에 비해 비용적으로 싸다면)한번 검토해볼만한 서비스인 것 같습니다.