Kubernetes 스케줄링 정리 3 - Pod Topology Spread Constraints 써보기
Karpenter를 구성하면서, Pod 스케줄링에 대한 이해가 부족하다는 것을 느껴서 정리중인 Pod 스케줄링 포스팅 중 세번째 인 Pod Topology Constraints 써보기 입니다. 저번 포스팅에서는 단순히 공식 문서를 토대로 필드 내 값들을 분석해보았는데요. 이번에는 간단하게 올려본 GKE 클러스터에 간단한 샘플 앱을 올려서 정말로 제약조건(Constraints)대로 골고루(Spread) 관리해주는지 확인해보려 합니다.
샘플 앱 구성
샘플 앱은 GKE 튜토리얼에 있는 hello-app 이미지를 배포하는 Deployment 자원입니다. 단순히 버전, 그리고 Pod이 뜬 Hostname을 출력해주는 앱입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-deployment
namespace: default
labels:
app: sample-deployment
spec:
replicas: 3
selector:
matchLabels:
app: sample-deployment
template:
metadata:
labels:
app: sample-deployment
spec:
containers:
- name: hello-app-1
image: us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0
imagePullPolicy: IfNotPresent
dnsPolicy: ClusterFirst
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
샘플 앱의 Pod은 5개의 Replica를 띄우게 설정하였습니다. 클러스터가 배포되어 있는 리전은 asia-northeast-3 리전으로, 3개의 Zone이 있습니다. 클러스터 내 노드는 일단 1개이고, 추가적으로 Zone 별 노드를 띄우며 Pod Topology Spread Constraints가 제대로 작동하는지 확인해보겠습니다.
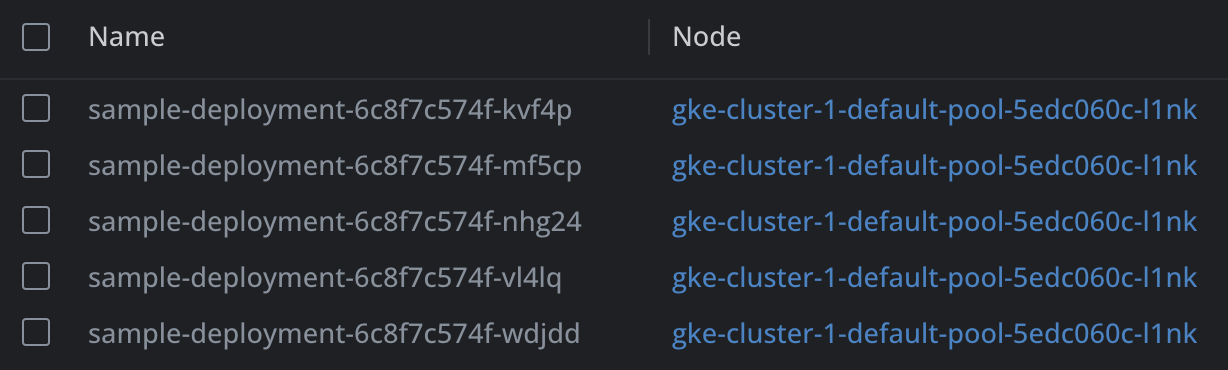
현재 상황을 보면, 한 노드에 다섯개의 Pod이 구동중인 것을 확인할 수 있습니다.
Pod Topology Spread Constraints 설정 및 확인
Deployment 내 Pod Spec에 Zone을 골고루 나누게 배포하는 기본적인 topologySpreadConstraints 설정을 추가합니다.
1
2
3
4
5
6
7
8
# ~ Pod Spec 내
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone # zone을 topologyKey로 사용해 나누어 배포
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: sample-deployment
이 경우, 한 Zone(예. asia-northeast3-a)에 여러 Node 가 떠있어도, 새로운 Zone(예. asia-northeast3-b)에 새로운 사용 가능한 노드가 있으면 그쪽으로 스케줄링을 하려 합니다. 최대 1개의 차이만(maxSkew) 허용하고, 그것을 만족하지 못하는 경우 새로운 Pod을 스케줄링 하지 않습니다(whenUnsatisfiable: DoNotSchedule)
이 때 한 Zone에만 Node를 띄워 두고 데모 워크로드를 배포한 뒤, 새로운 Zone에도 노드를 띄워 보겠습니다. 우리가 설정한 Pod Topology Spread Constraints 가 정상적으로 작동한다면, 새로운 노드가 스케줄링될 때 이미 있던 Zone에 있는 노드에 추가될 경우에는 maxSkew값이 1이 넘어가게 됩니다. 따라서, 이미 있던 Zone이 아닌 새로 추가된 Zone에 노드가 추가되게 됩니다.
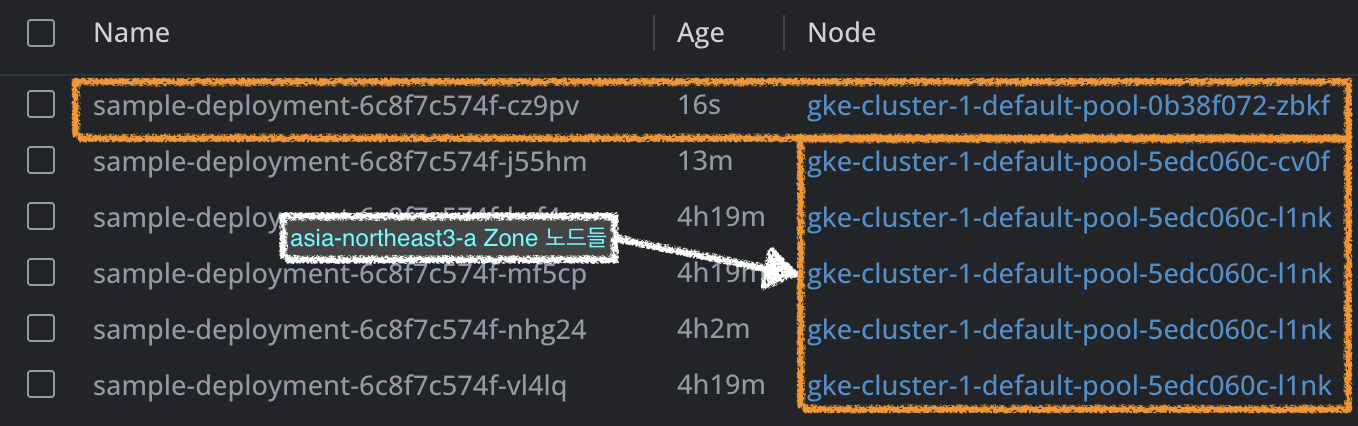
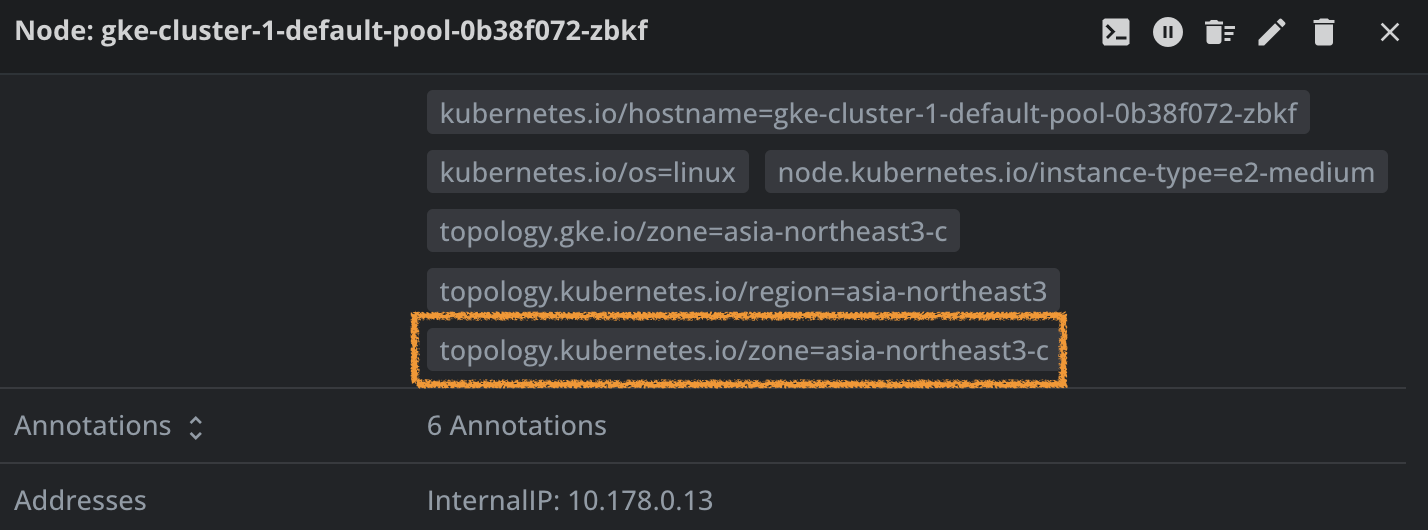
사진을 보면, 실제로 배포한 새 Pod이 배포된 노드는 이미 떠있던 노드들의 Zone이 아닌, 새로운 Zone인 asia-northeast3-c 에 있는 노드에 배포된 것을 확인할 수 있습니다. 이 후, 추가 배포되는 Pod들은 maxSkew 값을 맞추기 위해 앞으로도 계속 이 새로운 Zone 내 노드에 배포됩니다.
이렇게 우리는 노드가 떠있는 Failure Domain(CSP의 Zone이라던가, 노드가 설치되어있는 Rack이라던가…)를 신경쓰지 않고, 단순히 워크로드가 배포되는 레플리카 수만 조절하여 조금 더 안정성 있는 배포를 진행할 수 있습니다.
다른 예시
한 클러스터 안에서, 개발팀마다 서로 다른 Node Pool을 사용한다고 가정합니다. 예를 들어, 기본 Node Pool에는 외부에 서빙되는 서비스의 워크로드가 구동되고 별도의 저사양 Node Pool에서 사내 개발자들이 사용하는 개발자 플랫폼이 구동되고 있다고 생각해봅니다. 이 경우, 모든 개발 팀이 공통으로 각 Node Pool에 배포해야 하는 워크로드가 있을 수 있습니다. 서비스 observability 플랫폼이 사용하는 Pod 이라던가, 클러스터 내 공통 통신 Pod 이 그 예 중 하나가 될 수 있죠. Pod Topology Spread Constraints를 사용하면, 각 Node Pool을 일일히 확인한다거나 Pod AntiAffinity를 고려해서 워크로드를 배포하는 방법을 사용하지 않고 비교적으로 간단하게 Node Pool들을 고려해 골고루 배포할 수 있습니다.
위 예시에서, in-house-idp Node Pool이 추가되었다고 가정해봅니다. 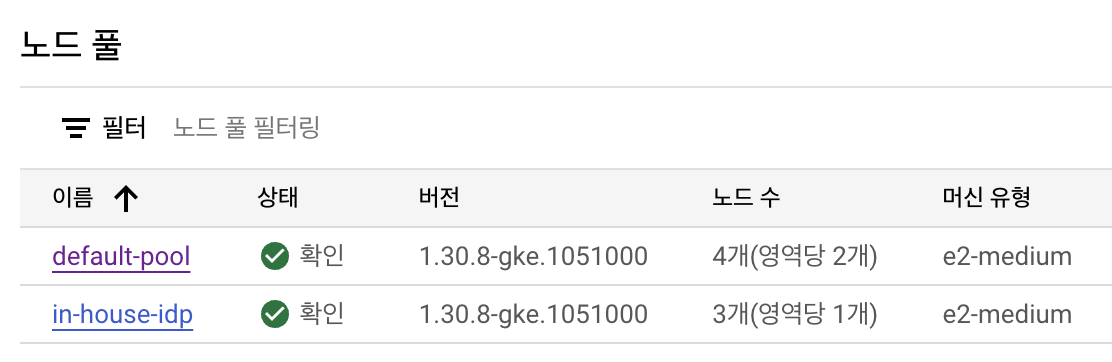
위에 언급한 니즈가 발생했을 경우, Pod AntiAffinity를 설정하기 위해 각 Zone 에 이미 Pod이 배포되어 있는 경우 배포하지 않게 설정하고… 할 필요 없이 단순히 우리가 설정했던 값에서 고려할 topologyKey를 바꿔주면 됩니다.
1
2
3
4
5
6
7
8
# ~ Pod Spec 내
topologySpreadConstraints:
- maxSkew: 1
topologyKey: cloud.google.com/gke-nodepool # CSP(GCP)에서 달아준 nodePool을 topologyKey로 사용해 나누어 배포
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: monitoring
그렇게 배포하면, 깔끔하게 각 Node pool 별로 배포가 된 것을 확인할 수 있습니다.

그런데 왜 안써요?
지금까지 Pod Topology Spread Constraints와 그 사용례를 알아봤습니다. 보통 K8s 를 사용할 경우, Cloud에 올려 사용하거나 CSP의 Managed Kubernetes 서비스를 사용하실 텐데 그 경우에는 각 노드에 정말 활용할 라벨이 많이 달려있거든요. 이 것을 활용해 스케줄링때 사용하고 계시다면, 한번 알아두시면 좋은 기능인 것 같습니다.
다만… 아직까지 기본적으로 이 것을 설정해서 사용하는 가이드나 튜토리얼은 조금 적은 것 같습니다. 이미 Affinity/AntiAffinity로도 잘 사용하고 있던 스케줄링이고, 한 번 설정해놓으면 뭔가 내 손을 떠나가는 느낌이라 스케줄링 방법/제약조건(각 서비스들이 꼭 사용해야 하는 Zone 이나, 각 Pod/서비스 간의 의존성..등)을 훤히 알고 있지 않으면 어떤 예외상황이 발생할지 모르겠다는 생각이 들어 약간의 불안감이 느껴졌거든요. 다만, 그렇다고 안쓴다 모른다 이러고 있는다기보단 어쩌다가 기본 값으로 들어오거나 언젠간 써야 할 수도 있는 기능을 알게 되어 좋았습니다.
아직도 이 기능들 안에는 Beta 딱지가 붙어있는 필드가 많습니다. Kubernetes 버전이 올라가면서 이 것들도 GA가 되고, 앞으로도 많은 기능이 추가 될거라 생각하니 이 분야가 어떻게 발전할지 기대가 됩니다.